


Lectures de plaques d’immatriculation : présent et avenir (prometteur)
La technologie de lecture automatique des plaques d’immatriculation ou LAPI (License Plate Recognition, LPR) permet d’obtenir des données relatives à la plaque minéralogique d’un véhicule à partir d’une image ou d’un groupe d’images. Ces dernières années, la reconnaissance des plaques minéralogiques est un domaine de la vision artificielle ou Computer Vision (CV) dont l’utilisation s’est largement répandue dans différents secteurs liés à la surveillance des véhicules : sécurité routière, contrôle d’accès aux parkings ou systèmes de péage automatique et de stationnement, entre autres.
Comment et quand le lecteur de plaques d’immatriculation est-il devenu nécessaire ?
Les premières références à un système LAPI remontent à 1976, lorsque la Police Scientific Development Branch du Royaume-Uni a mis en œuvre le premier système, qui est devenu opérationnel en 1979. Outre les défis techniques, auxquels doit souvent faire face l’équipe de recherche, l’objectif de cette application était clair dès le départ : augmenter la sécurité. Depuis lors, ce système a beaucoup évolué, aussi bien au niveau technique que des domaines d’application.
Quelle a été l’évolution de la technologie d’identification des plaques d’immatriculation au fil du temps ?
Au début, ces systèmes étaient constitués de deux parties clairement différenciées : les optiques, composées de caméras optimisées pour une bonne capture d’image ; et une unité centrale (UC) externe avec une puissance de calcul suffisante pour traiter la reconnaissance optique de caractères (Optical Character Recognition OCR) dans un délai raisonnable. Bien que ce premier modèle puisse encore être valable, l’évolution des unités centrales vers des composants plus petits, plus puissants et moins chers a fait évoluer les systèmes vers des dispositifs compacts, leur donnant beaucoup plus de polyvalence.
Au cours des dernières années, l’intelligence artificielle (IA) a révolutionné la programmation. Même si l’IA semble être un concept très récent, les premières références remontent aux années 1950. En 1956, lors de la conférence de Dartmouth, un petit groupe de différents domaines d’expertise s’est réuni et a concentré son attention sur le monde naissant des ordinateurs et leur capacité potentielle à présenter un comportement intelligent.
Depuis lors, de nombreux progrès ont été effectués dans ce domaine et, au cours de la dernière décennie, une nouvelle technologie a révolutionné le monde de l’intelligence artificielle : l’apprentissage profond ou Deep Learning (DL). Cette méthodologie est une branche de l’apprentissage automatique ou apprentissage machine, le Machine Learning, qui consiste à apprendre par l’exemple. Un modèle pouvant évaluer des exemples et une petite collection d’instructions pour modifier le modèle lorsque des erreurs se produisent est créé. Le système doit être capable d’apprendre de sa propre expérience de manière autonome et, au cours du processus d’entraînement et d’apprentissage, il doit pouvoir extraire des modèles qui lui permettent de résoudre un problème complexe avec beaucoup de précision. L’une des techniques de mise en œuvre de l’apprentissage profond les plus courantes est l’utilisation de réseaux neuronaux.
Que sont les réseaux neuronaux et comment fonctionnent-ils ?
Les réseaux neuronaux artificiels sont un modèle qui s’inspire du fonctionnement du cerveau humain. Ils sont constitués d’un ensemble de nœuds appelés neurones artificiels qui sont regroupés en couches et forment un réseau neuronal. Les nœuds sont connectés les uns aux autres pour qu’un signal à l’entrée puisse être transmis pour générer une sortie. Chaque neurone a un poids, qui correspond à une valeur numérique qui modifie l’entrée reçue. Les nouvelles valeurs générées quittent les neurones et continuent leur chemin à travers le réseau, obtenant une sortie qui sera la prédiction calculée du réseau. Plus il y a de couches, plus le réseau est complexe et, par conséquent, plus les problèmes qu’il sera en mesure de résoudre sont complexes.
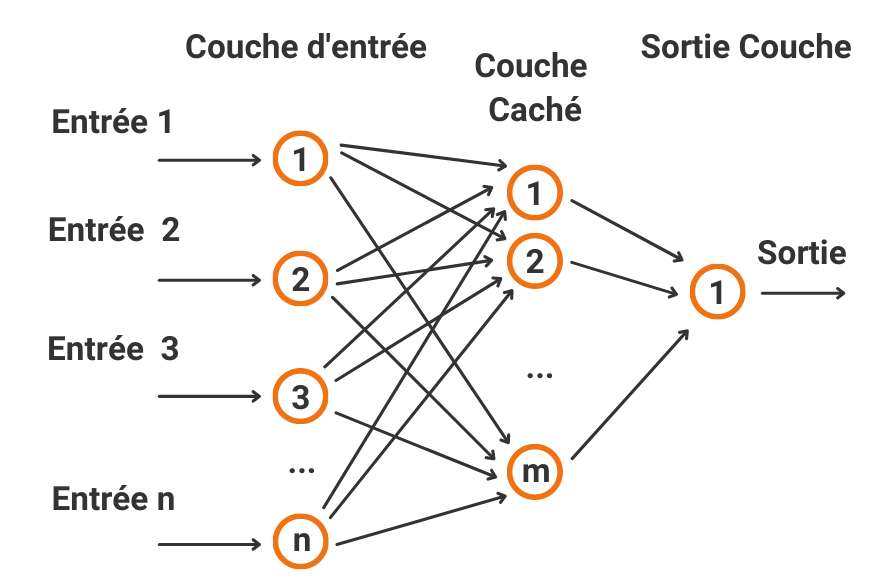
Le principal objectif de ce modèle est qu’il soit capable de se modifier pour pouvoir effectuer des tâches complexes qui ne pourraient pas être programmées par la programmation classique à base de règles. Cette procédure est effectuée au cours du processus d’entraînement, où des données sont introduites en entrée et, en fonction du résultat obtenu, les poids des neurones sont modifiés en fonction de l’erreur obtenue. Cette méthode est connue sous le nom de Backpropagation ou rétropropagation. De cette façon, le réseau apprend automatiquement jusqu’à l’obtention des résultats souhaités, ce qui les rend très précis.
L’apprentissage profond appliqué à la technologie de lecture des plaques d’immatriculation
Afin que le processus de lecture soit efficace, de nombreux défis doivent être relevés par les personnes qui participent à la recherche et au développement dans le domaine de l’identification des plaques minéralogiques. D’une part, le système doit être rapide et efficace dans différentes conditions de capture d’images : conditions d’éclairage (jour ou nuit), position et spécifications de la caméra (angle, perspective, distance ou résolution). D’autre part, la grande variété de typologies de plaques minéralogiques utilisant des couleurs, des polices et des alphabets différents présente un défi technique complexe mais stimulant pour la lecture des plaques d’immatriculation.
La discipline de l’apprentissage profond est en plein essor ces derniers temps grâce à son application dans le monde des mégadonnées, le Big Data, et de l’IDO, l’internet des objets. Cette poussée évolutive s’applique également au monde de la LAPI pour poursuivre l’objectif principal du secteur : s’améliorer, chercher de nouveaux horizons de perfection. Il convient de noter que les techniques classiques de vision artificielle ont atteint leurs limites techniques et ne font pas partie des technologies de pointe, du moins dans les scénarios non contrôlés, car aucune règle ne peut être programmée pour traiter les combinaisons infinies de données d’entrée qui se produisent dans le monde réel.
Ainsi, si chaque étape du processus d’identification des plaques d’immatriculation est transformée en un problème d’optimisation avec une distribution d’erreurs complexe, nous pouvons bénéficier de l’apprentissage profond et atteindre des taux de réussite très élevés. Mais cela nécessite une quantité de mémoire et un temps de traitement différents de ceux utilisés jusqu’à présent. C’est pourquoi, afin d’obtenir des temps de réponse efficaces dans des modèles plus ou moins complexes, des unités de traitement spéciales sont utilisées, telles que des processeurs graphiques, les Graphic Processing Units (GPU), ou des unités de traitement neuronal, les Neural Processing Units (NPU).
L’histoire se répète
Nous sommes actuellement à un tournant similaire à celui que nous avons connu il y a quelques années avec les unités centrales : la technologie n’est pas assez bon marché pour être utilisée à grande échelle. Cela ouvre la porte à deux possibilités principales : relever le défi d’un système compact All-in-One intégré où l’évolution du matériel a encore (raisonnablement) beaucoup de chemin à parcourir, ou bien en finir avec la philosophie du All-in-One en effectuant le traitement d’apprentissage profond sur un serveur externe (ou nuage). La technologie progresse très rapidement et ce qui est irréalisable aujourd’hui pour des raisons de coût pourrait être totalement accessible dans quelques mois. L’avenir est plein de possibilités et ce qui est certain, c’est qu’elles améliorent toutes la qualité et l’efficacité globales de nos systèmes de lecture de plaques d’immatriculation ou LAPI.
Un avenir prometteur
En conclusion, la technologie LAPI est loin d’être stagnante. L’émergence de l’apprentissage profond lui donne un nouvel élan qui peut nous permettre d’atteindre des taux de réussite extrêmement élevés et, ainsi, de résoudre des situations complexes de manière beaucoup plus agile que par le passé. C’est le bon moment pour continuer à investir dans la recherche dans ce domaine et, depuis Quercus Technologies, nous voulons continuer sur cette voie pour fournir les meilleures solutions de stationnement à notre clientèle et résoudre leurs problèmes.
R&D Computer Vision Team Responsible chez Quercus Technologies
NOUVELLES QUI PEUVENT VOUS INTÉRESSER ...

Nous contacter
Que vous cherchiez des réponses, que vous vouliez plus d'informations, que vous souhaitiez résoudre un problème ou simplement nous donner vos impressions, n'hésitez pas à nous contacter.
Nous serons ravis de vous aider !